The AI agent I built for this blog answers questions by searching a Supabase vector store. But that store doesn’t fill itself — something has to read the blog posts, chunk them, embed them, and push them in. I was doing this manually. This pipeline automates it.
The Problem with Manual Ingestion
Every time I publish or update a post, I’d have to manually trigger the embedding workflow. That’s fine for a handful of posts, but it doesn’t scale and it’s easy to forget. The fix is a workflow that knows what’s already indexed, what’s changed, and only does the work that’s actually needed.
How the Pipeline Works
There are two entry points: a Manual Trigger for on-demand runs, and an RSS Trigger configured to poll at midnight each day — so new or updated posts get picked up automatically overnight without any manual step. The first thing either path does is an RSS Feed Read node that pulls from the blog’s RSS feed, using a custom apiUrl field to get each post’s full content URL alongside the standard feed metadata.
From there, each RSS item fans out in two directions in parallel:
- A Blog Content HTTP Request node fetches the actual article body from
apiUrl - A Get Document Count Postgres query checks whether that post already exists in
blog_documentsby itsdocument_id
Both results are merged back together so the next node has both the content and the existence flag.
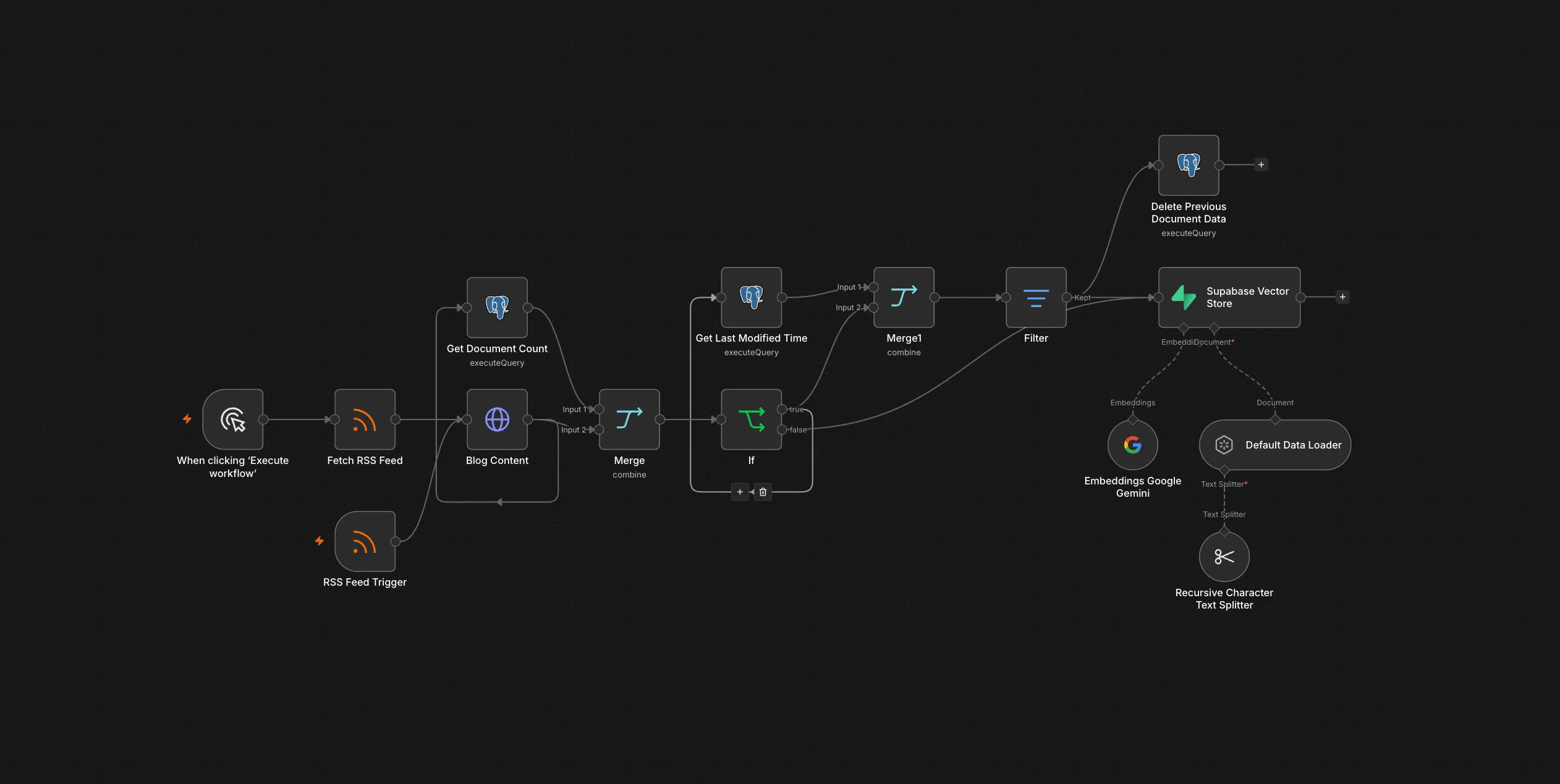
The complete ingestion workflow in n8n — RSS feed read, existence check, update logic, and Supabase embedding in one pipeline.
The Smart Update Logic
This is the part that makes it efficient. An If node branches on whether the document already exists:
If it doesn’t exist — new post, go straight to embedding and insertion.
If it does exist — run a second Postgres query to get the last_modified timestamp from the stored metadata. Then a Filter node checks whether that timestamp matches today’s date. If the post hasn’t been touched today, it gets skipped entirely. If it has been updated, the old chunks are deleted first, then the post is re-embedded and re-inserted clean. The assumption here is that you run the sync on the same day you publish or edit — which holds for a manual trigger, and would hold for a deploy-triggered run too.
That delete-before-reinsert step is important. Without it, updating a post would stack duplicate chunks in the vector store — the agent would start pulling stale content alongside the new version.
The Embedding Side
Once a document clears the routing logic and is ready to insert, it flows into a Supabase Vector Store node in insert mode, pointed at the blog_documents table.
Three sub-nodes hang off it:
- Gemini Embedding 2 (
models/gemini-embedding-2) generates the vectors — same model used on the retrieval side, which matters for cosine similarity to work correctly - Default Data Loader reads from
$json.bodyand attaches metadata:document_id,created_time, andmodified_time - Recursive Character Text Splitter handles chunking before the loader hands content to the embedder
The metadata on each chunk is what makes the update logic possible — querying by document_id to find existing records, and reading modified_time to decide whether a re-embed is needed.
What’s Next
The midnight poll covers most cases — by the time the next day rolls around, any post published the day before is indexed. The gap is same-day freshness: if you publish and someone asks about it within hours, the vector store won’t have it yet.
The tighter solution is a deploy-triggered sync. Vercel webhooks are the natural choice, but they’re a paid feature. The free alternative is GitHub Actions — Vercel writes deployment_status events to GitHub on every deploy, so a workflow can listen for production success and call the sync endpoint immediately after a deploy lands, no paid plan needed.
This pipeline was also the starting point for the full rewrite: once I moved from n8n to a Django-based RAG package, the same logic — RSS read, existence check, delta sync — moved into a management command running in the same app as the rest of the backend.